Question:- To generate a star pattern using Informatica depending on the number of rows in the input file
Suppose there are 7 rows in the source file (any type of data), the target should have 7 rows of stars in the following pattern:-
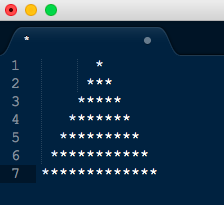
Fig1
Solution:-
There are two ways of doing this – first is to use a Java transformation in passive mode and second is without using a java transformation.
Doing it WITHOUT a Java transformation is challenging hence I will describe this method in this post. Java transformation based solution will be posted later.
Solution with Java Transformation
We can observe the following about the pattern we are generating:-
1. First line has 7 spaces before the star, second has 6 and so on. Hence the spaces in front are decreasing by 1 for each row. The number of spaces in first row is equal to the number of rows in the source file and number of spaces in front for the last row is zero
2. The number of stars are increasing by two after the first row. 1,3,5 and so on
As we are doing this without a java transformation, the trick lies in how we generate variable number of stars and spaces for each row.
Algorithm:-
1. First generate only the stars as in below pattern
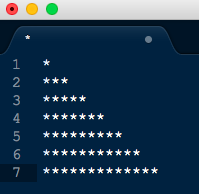
Fig2
2. Sort the above pattern in descending order to generate the pattern below
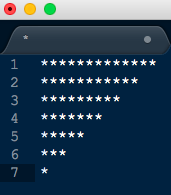
Fig 3
3. Add spaces to the pattern, starting with zero spaces in first line and increasing it by one for each subsequent row to get the following pattern:-
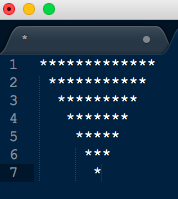
Fig 4
4. Sort again, this time in ascending order to get the final pattern
Fig 5
The mapping will also include one pipeline to get the count of the rows in the file. This will be used in the main flow to generate the star pattern.
Complete mapping will look like below (click on the image to enlarge):-

Mapping Variable:- $$ROWCOUNT
Target Load Plan:- SQ_FF_TEST_SRC first (to count the number of rows)
Mapping Explanation:-
First pipeline to count number of rows in the file
1. Use an aggregator to count the number of rows in the file like below (agg_count_rows)

2. Use an expression transformation to assign the count value to a mapping variable (exp_set_row_count_variable)

3. Connect both ports from the above expression to a dummy target file.
Second Pipeline to produce star pattern
1. Expression to get the row count variable value in the pipeline and also generate a sequence for each row starting from one (exp_seq_row_count)

2. Expression to generate intermediate start pattern as in Fig 2 above (exp_int_star_pattern)
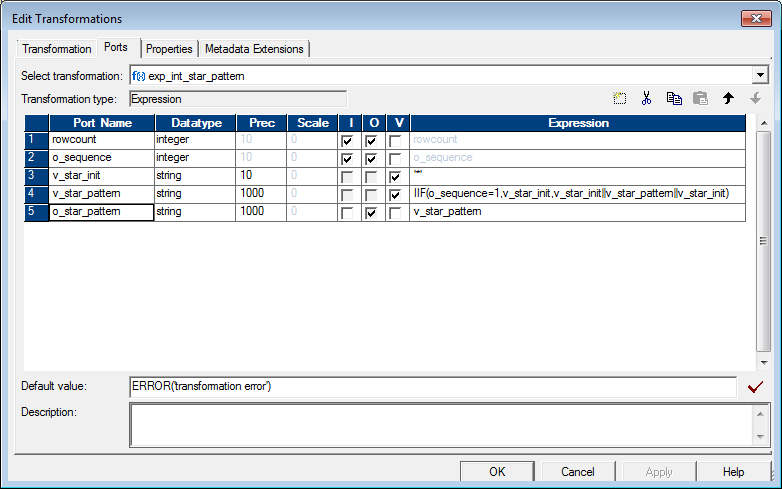
3. Sorter to sort the intermediate pattern in descending order (sort_desc)

4. Expression to add spaces to the sorted pattern (ex_add_spaces_to_pattern)

5. Sorter to again sort the pattern in ascending order to generate the final star pattern (srt_final_pattern)
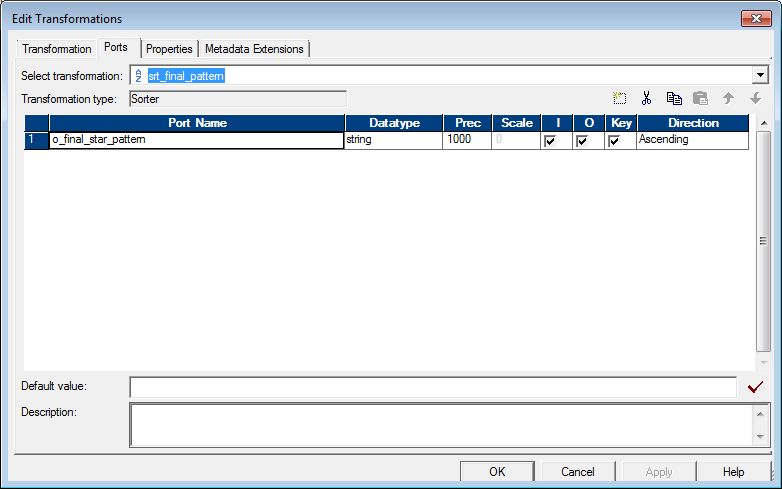
Place a source file with any number of rows, result you will get is lot of stars!!
Let me know in comments if you need any clarifications or if you have any feedback.